
近些年来,AI大模型呈现出迅猛的发展态势,这一趋势对算力提出了前所未有的高要求。面对持续上涨的AI算力需求,国产GPU公司唯有发展自己的大规模AI算力集群,才能突破围追堵截,走上康庄大道。在此背景下,摩尔线程推出了“夸娥智算集群”。如今经过持续迭代升级,尤其是搭载最新一代智算卡MTT S5000后,整个集群在硬件算力、软件协同和系统效率方面取得长足进步,为AI时代打造坚实算力底座。
最新数据显示,基于S5000的千卡智算集群,其计算效率超过同等规模国外同代系GPU训练集群。这意味着,国产GPU智算平台在支撑前沿AI训练的关键能力上,已能与国际领先水平看齐。

夸娥(KUAE)智算集群:为前沿大模型训练而生
夸娥(KUAE)智算集群是摩尔线程为应对大模型训练与推理的规模化算力需求所打造的系统级算力解决方案,支持从千卡到万卡级别的灵活部署,单集群可部署超过1000个计算节点,每个节点集成8颗摩尔线程自研OAM模组化形态的GPU,并通过优化的3D全互联拓扑实现了极低的通信延迟,能满足大模型时代对于算力“规模够大+计算通用+生态兼容”的核心需求,为像DeepSeek这样的千亿参数大模型预训练提供稳定且高效的算力支撑。
在技术层面,夸娥(KUAE)智算集群的突破点在于解决大模型训练的核心挑战:支持复杂架构:为MoE混合专家模型、多模态模型等前沿复杂AI架构提供理想的训练环境;高效计算与通信:通过计算与通信协同编排技术,实现了跨节点高效数据交换和同步,显著降低了分布式训练中的通信开销;超长稳训练保障:针对AI模型长时间训练需求,强化集群可靠性,同时配备全面的集群可观测性系统,实时监控计算资源利用率、网络拓扑状态和训练进度,确保智算级别集群在数周乃至数月的连续训练中保持稳定高效;突破显存与效率瓶颈:集成数据并行、张量并行和流水线并行等多维并行策略,支持3D/4D混合并行计算框架,有效应对超大规模参数模型的显存挑战,提升计算效率。
全栈AI布局:芯片到集群的完整拼图
夸娥(KUAE)智算集群的成功运行,展现了摩尔线程在AI算力领域从芯片到系统的全栈布局能力。据悉摩尔线程的产品线丰富多元,能充分满足多样化的市场需求。比如支持FP8精度的最新智算卡MTT S5000、训推一体全功能智算卡MTT S4000以及支持万卡互联的第二代方案KUAE2等等,这些产品涵盖大模型训练、推理和科学计算应用场景,已实际交付多个智算中心。
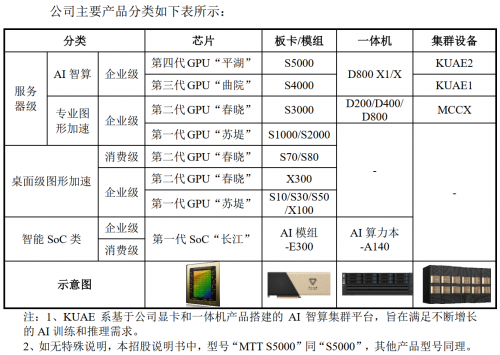
在关键技术方面,摩尔线程是国内少数掌握FP8计算精度的国产GPU厂商,在全球与英伟达保持技术同步。其全功能国产GPU可高效满足DeepSeek V3/R1等大模型的的FP8原生计算需求,具有广泛的产业应用前景。此外,摩尔线程还构建了支持FP8、BF16、FP32等混合精度训练方案。目前,夸娥集群已全面适配DeepSeek、Qwen、GLM、Aquila、GPT、LLaMA等主流大模型架构,构建了完整的国产化算力支持体系。
摩尔线程近些年来一直坚持在国产GPU领域不断深耕,不仅凭借全栈自研能力筑牢了技术根基,更以开放的“KUAE + MUSA”生态凝聚了产业合力,稳步推动了国产GPU事业向前发展。
 【广告】免责声明:本内容为广告,不代表蚌埠新闻网的观点及立场。所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。蚌埠新闻网登载此文出于传递更多信息之目的,对此文字、图片等所有信息的真实性不作任何保证或承诺。文章内容仅供参考,不构成投资、消费建议。据此操作,风险自担!!!
【广告】免责声明:本内容为广告,不代表蚌埠新闻网的观点及立场。所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。蚌埠新闻网登载此文出于传递更多信息之目的,对此文字、图片等所有信息的真实性不作任何保证或承诺。文章内容仅供参考,不构成投资、消费建议。据此操作,风险自担!!!